
Contenido principal
Alfa 55
 Descarga la revista completa
Descarga la revista completa El aprendizaje de las máquinas

La clave de la explosión actual de los sistemas de inteligencia artificial es haber conseguido máquinas capaces de adquirir, e incluso generar, nuevos conocimientos, más allá de la información que se les ha suministrado previamente. Pero ¿pueden las máquinas aprender? En tiempos de inteligencia artificial (IA), en los que las noticias, las promesas y las dudas proliferan, hay un abanico de términos nuevos para la sociedad que empiezan a sernos cada día más familiares. Es el caso del aprendizaje automático, a menudo mencionado por su expresión en inglés, machine learning, y que se refiere precisamente a la capacidad de las máquinas para aprender a partir de los datos que van adquiriendo y analizando por si solas.
Texto: Patricia Ruiz Guevara | periodista de ciencia
Aunque resulte muy tecnológico y actual, el término machine learning no es nuevo. Su origen se remonta al siglo pasado, pero los entendidos no se ponen de acuerdo con la fecha exacta. Hay quien se refiere al año 1943 y al artículo científico A logical calculus of the ideas immanent in nervous activity de Walter Pitts y Warren McCulloch, en el que se presenta el primer modelo matemático de redes neuronales. También quien señala a 1952 y Arthur Samuel, empleado de IBM y pionero en el campo de los juegos de ordenador y la IA, que escribió el primer programa de ordenador capaz de aprender y acuñó el término. Inevitablemente, también aparece el nombre de Alan Turing.
Sea como fuere, la IA y, en concreto, el aprendizaje automático están viviendo ahora su momento de esplendor. ¿Cuánto hay de burbuja y cuánto de real? ¿Qué aplicaciones ya estamos viendo y cuáles tienen potencial para transformar el mundo?
Para empezar, conviene discernir qué es el aprendizaje automático y qué tiene que ver con la inteligencia artificial. Lo segundo es lo más sencillo de ubicar: el machine learning es un tipo de inteligencia artificial, una rama concreta de esta tecnología que, de alguna manera, ha aprendido a aprender, es capaz de absorber una gran cantidad de datos, encontrar patrones entre ellos y sacar conclusiones. “No toda la inteligencia artificial es machine learning, pero todo el machine learning sí es inteligencia artificial”, aclara Jon Ander Gómez, profesor de la Escuela Técnica Superior de Ingeniería Informática de la Universitat Politècnica de València y fundador de Solver Intelligent Analytics.
En concreto, Gómez detalla que estos modelos tienen detrás un fundamento matemático estadístico que los hace capaces de aprender a partir de los datos. “Un modelo de machine learning es un modelo matemático que ha sido entrenado para realizar una tarea concreta a partir de un amplio conjunto de datos de muestra”, define también Manuel Jesús Marín, doctor en Informática y profesor de la Universidad de Córdoba. Esos modelos están formados por “un conjunto de parámetros que hay que ajustar durante el proceso de entrenamiento en función de las muestras usadas”, añade Marín.

Parta llevar a cabo ese entrenamiento, “existen diferentes algoritmos, como pueden ser las redes neuronales, los modelos generativos, los clasificadores bayesianos, el reinforcement y el federated learning, entre otros”, explica Angélica Reyes-Muñoz, investigadora de la Universidad Politécnica de Cataluña especializada en vehículos autónomos e IA.
La catedrática de la Universidad de Alcalá María Dolores Rodríguez, que investiga en machine learning, lo explica con un ejemplo que incluye visión artificial: “Imaginemos que queremos enseñarle a un ordenador cómo identificar imágenes de perros. En lugar de decirle exactamente cómo es un perro, podemos mostrarle muchas imágenes de perros y decirle: estos son perros. Los modelos analizarán las imágenes y encontrarán patrones comunes que definen a un perro, como por ejemplo el hocico y no tener bigotes. Luego usará este conocimiento para identificar perros en nuevas imágenes que nunca había visto”.
Dentro de los algoritmos de aprendizaje automático hay distintos tipos, diferencia Gabriel Benítez, científico de datos principal de Quant AI Lab. Por un lado, “los algoritmos supervisados, en los que conocemos la variable objetivo y son entrenados a partir de datos etiquetados, y que aprenden a partir de la relación entre las variables dependientes y la variable objetivo”. Por otro lado, están “los algoritmos no supervisados, que trabajan con datos no etiquetados y su principal función es encontrar patrones en los datos; los algoritmos no supervisados más comunes son los de clustering y algoritmos de recomendación”. También existen los semisupervisados, recuerda Marín.
Siempre que utilizamos el verbo aprender hay que pensarlo entre comillas: en realidad, el modelo de IA no entiende lo que está aprendiendo, simplemente es una automatización; no está el aspecto humano del aprendizaje.
El deep learning
Otro término que circula en estos tiempos es el deep learning o aprendizaje profundo. En este caso, se trata de un tipo de machine learning, un subtipo de algoritmos específicos que “se basan en redes neuronales para aprender y extraer características de datos complejos como pueden ser imágenes, textos o sonidos”, indica Benítez. Es decir, si imaginamos una serie de conjuntos, el más grande sería la inteligencia artificial, dentro estaría el aprendizaje automático, y dentro de este un subconjunto sería el aprendizaje profundo.
Reyes-Muñoz señala también una diferencia clave: “El machine learning aprovecha datos estructurados y etiquetados para hacer predicciones, mientras que los algoritmos de deep learning eliminan parte de estas necesidades de preprocesado, ya que pueden trabajar con datos no estructurados y extraer características de forma automatizada”. Por tanto, no necesitan de la intervención humana para ese etiquetado.
Ahora parece que todo es (o puede ser) inteligencia artificial, que el aprendizaje automático es la panacea que solucionará los problemas de todas las empresas y, claro, se abusa a menudo del término. Sin embargo, los expertos nos recuerdan que debemos alejar tanto hype (exageración) del asunto: no dejan de ser matemáticas, operaciones, reglas y datos; y no todo es IA, a veces es estadística o informática.
“El término inteligente se utiliza de forma muy distendida, pero no todo pertenece a la inteligencia artificial. Programar una serie de reglas en una aplicación móvil puede dar la sensación de ser inteligente, pero no hay ni modelos ni algoritmos que lo sustenten, que son aspectos en los que se basa la IA”, detalla Rodríguez.
La experta siente que se tiende a pensar en el aprendizaje automático como una solución mágica, que puede resolver cualquier problema sin esfuerzo. Pero, en realidad, “requiere una cuidadosa preparación de datos, ingeniería de características y selección de modelos para lograr buenos resultados; no es una solución rápida, requiere experiencia en el dominio y experimentación iterativa”.
“Es cierto que el machine learning va a afectar y ya está afectando directamente a la forma en que trabajamos, nos relacionamos, consumimos y hasta jugamos. Pero también es verdad que hay mucho fake y mucha exageración sobre cómo esta tecnología puede resolver problemas complejos”, considera Rafael Casuso, director general de Tecnología en ThePower Business School.
Benítez coincide: “Creo que uno de los mitos que se ha generado es que el machine learning es para todo tipo de empresas, y la verdad es que es necesario tener una infraestructura de datos adecuada antes de poder aplicarlo”. Eso sí, subraya, cada vez más compañías y sectores empiezan a implementarlo.
Aplicaciones
¿Cómo y dónde se implementa? Preguntamos a los expertos y expertas y coinciden: sí, hay mucho autobombo, pero también vivimos rodeados de ejemplos prácticos de aprendizaje automático en el día a día, desde los algoritmos de recomendación que utilizan Netflix, Amazon y Spotify a los asistentes de voz, como Siri o Alexa, recuerda Casuso. También en el sector financiero, para realizar transacciones, y en salud para “optimizar el uso de las pruebas diagnósticas y los tratamientos para mejorar la atención al paciente”. 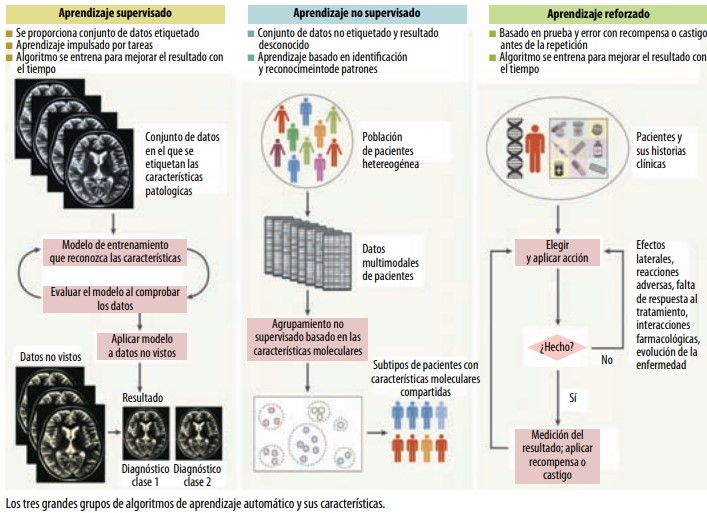
También de aplicaciones en salud hablan Gómez y Rodríguez. “Estamos trabajando con el Hospital de la Defensa Gómez Ulla y el Hospital Universitario de Guadalajara en modelos de aprendizaje automático que pueden predecir con bastante precisión el número de pacientes diarios o semanales de ambos hospitales. Esto puede ayudar a gestionar mejor los recursos y reducir las listas de espera”, indica la investigadora de la Universidad de Alcalá.
Gómez, de la Universitat Politècnica de València, ha trabajado con machine learning para investigar el alzheimer, las migrañas y el cáncer. Para las migrañas, usan el análisis de electroencefalogramas, el registro de la actividad bioeléctrica cerebral, para “buscar patrones y observar si hay cambios antes de que el paciente sufra la migraña, para que se pueda tomar la medicación con anticipación, conseguir que no llegue a tener el episodio y acabe teniendo que tomar menos tratamiento”. En el caso del cáncer, han entrenado un modelo con imágenes médicas para detectar zonas con mayor actividad metabólica y obtener la probabilidad de que el área corresponda o no a un tumor. “Se entrena un modelo por cada patología objetivo y nos devuelve una probabilidad, a partir de ahí el personal médico es quien puede interpretar ese resultado”.
Cambiando de tercio, Benítez incide en usos dentro de la industria, como algoritmos para la detección e identificación de distintos tipos de gases mediante reconocimiento de imágenes satelitales, y la optimización de inventarios utilizando datos históricos. “Otro ejemplo podría ser para estrategias de pricing dinámico en el área comercial, es decir, a partir de las características de cada cliente, predecir un precio óptimo”, dice.
Dentro de la industria energética, Rodríguez ha trabajado con dos becas Marie Curie gracias al programa GotEnergyTalent (parcialmente financiado por la Universidad de Alcalá y la Unión Europea) y ha investigado sobre modelos de machine learning que “pueden ayudar a la predicción de los consumos energéticos, así como a la predicción de la producción en energías renovables (por ejemplo, parques eólicos o parques fotovoltaicos)”. A partir de ahí, “se puede intentar optimizar la oferta y la demanda para ofrecer mejores precios a los consumidores”, explica la investigadora.
Otro tema en el que se está utilizando es el de los coches autónomos. ReyesMuñoz pertenece al grupo de investigación Icarus (Intelligent Communications and Avionics for Robust Unmanned Aerial Systems) de la Universidad Politécnica de Cataluña y cree que pronto “los vehículos autónomos, tanto de tierra como del aire, serán una realidad de la vida diaria en la que convivirán de manera natural la predicción del comportamiento humano y distintos sistemas de inteligencia artificial capaces de interactuar con las innumerables formas en que las personas nos comunicamos con las máquinas”, vaticina. También recuerda la importancia del machine learning para las smart cities, las ciudades inteligentes que, a través de sensores, recopilan millones de datos.
Y de la urbe nos vamos al campo, porque el aprendizaje automático se puede utilizar para la detección de frutos y el mapeo de la producción agrícola. Esto ayuda al agricultor a predecir la cosecha, planificar la campaña de recolección, el almacenamiento y las estrategias comerciales, y también a encontrar las áreas menos productivas de la plantación, descubrir las razones de esta menor producción y proponer soluciones, como detallaron investigadores de la Universitat de Lleida en su artículo “Cómo la inteligencia artificial nos ayuda a contar manzanas”, en The Conversation.
Mientras la IA cuenta manzanas, nosotros contamos usos del aprendizaje automático para que la próxima vez que leamos el término en una noticia podamos saber si esta rama de la inteligencia artificial es (o no) hype.